




Camera calibration in the Vision SDK is essential for properly positioning features detected and classified in the map. The Vision SDK has now processed more than 1 billion images -- and in doing so identifies and refreshes 15M+ traffic signs in the United States. As Vision gathers more observations from connected cameras, the richness and accuracy of our maps improve, building a better platform for developers and a better experience for their users.
Accurately determining the geographic location (latitude, longitude, elevation) of a feature observed with an arbitrary camera has two components: 1) the vector pointing from the center of the earth to the camera, and 2) the vector pointing from the camera to the feature. Determining the first vector is made possible by the fact that so many of today’s cameras are in devices also equipped with GPS receivers, which gets to within 5-10 meters in most cases. Assuming these cameras are attached to vehicles traveling through a known road network, we can substantially reduce the camera’s position error through map matching. Further improvements in accuracy are possible with innovations such as dual-band GNSS and dead reckoning systems.
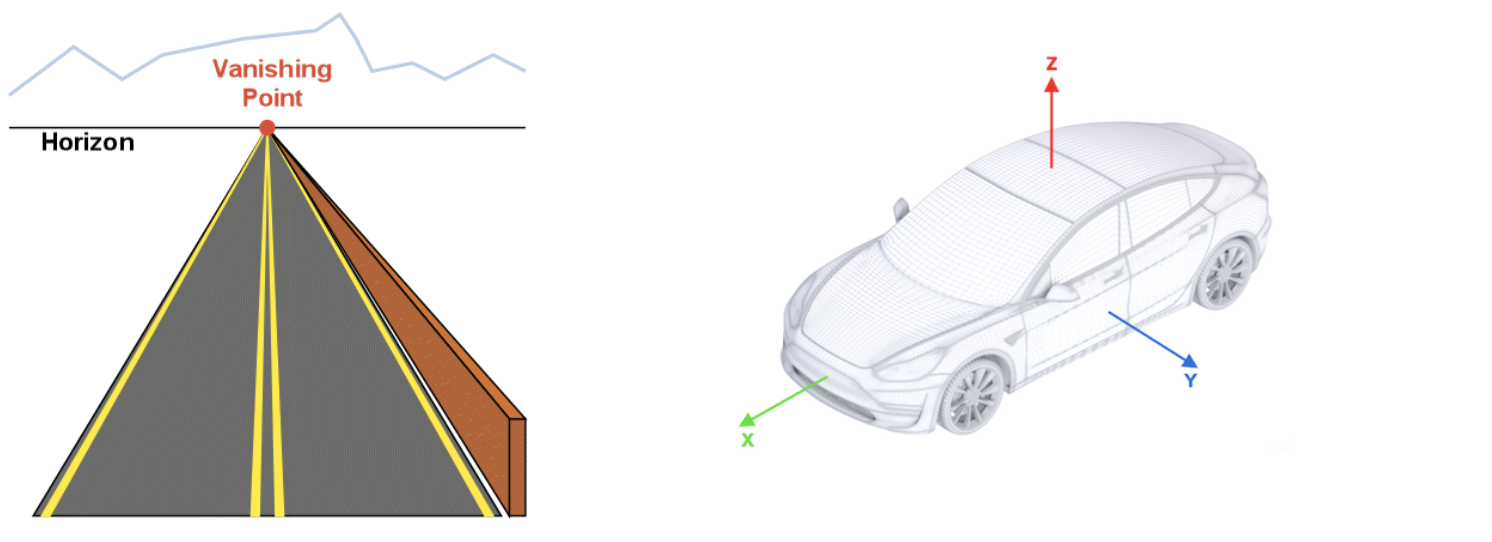
Determining the second vector involves getting from the x and y pixel coordinates of a feature in a 2D camera image to a 3D vector connecting the camera lens to the feature of interest. Getting from an object’s pixel coordinates to latitude and longitude requires Vision to estimate the extrinsic parameters of the camera (i.e. how it is mounted on the vehicle), but in the real world the camera extrinsics are often inaccurate or missing altogether. Vision’s dynamic camera calibration algorithm estimates the camera pose relative to the vehicle using 6 components: 3D translation (x, y, and z) and the 3 Euler angles (roll, pitch, and yaw) for rotation.

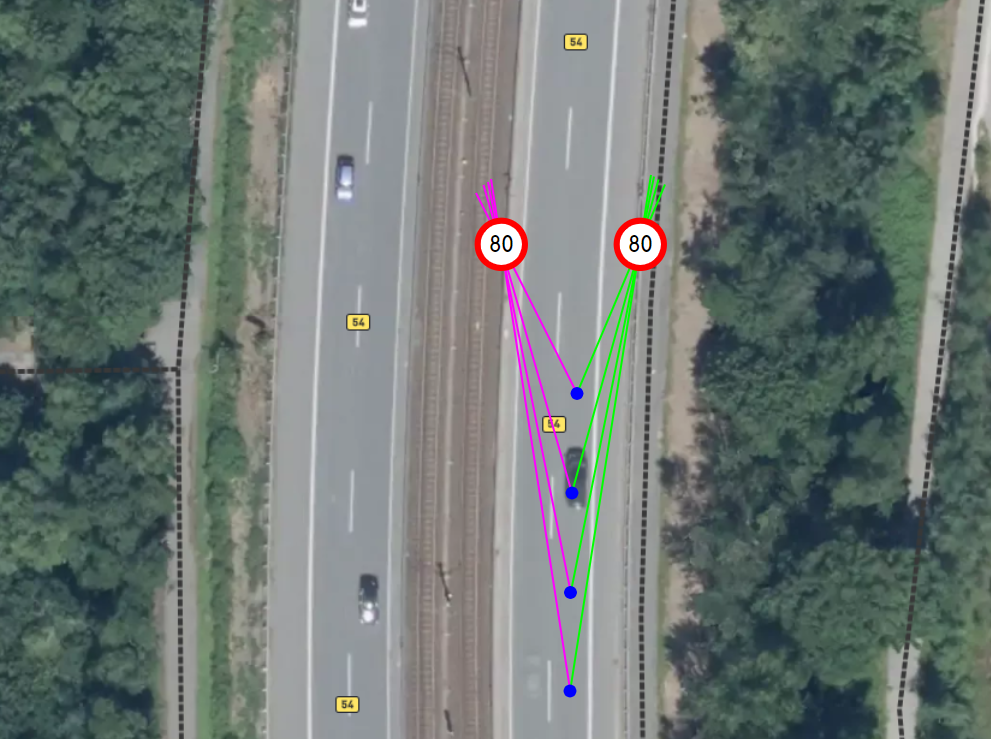
The calibration procedure aligns the origin of the vehicle’s coordinate system with camera position such that the x- and y-coordinates for camera translation are 0, while the unknown z-coordinate is the height of the camera above the road surface. Currently the calibration algorithm does not estimate the camera height, but allows a value provided by the client application through the public API, and if none is provided, defaults to 1.3 meters. The calibration algorithm allows estimation of pitch and roll angles, with a default yaw angle of 0°. Camera angles are estimated through the calculation of the vanishing point (VP) on the image plane, where projections of parallel lines from the real world intersect. The projections of the vehicle’s x-axis and the horizon line (which is parallel to the vehicle’s y-axis) go through this point, so there is a direct connection between the camera's orientation and the coordinates of the vanishing point in the frame.
In an ideal world it's enough to have two crossing lines to find the vanishing point, but in practice the Vision SDK needs to collect many noisy observations of the lines that intersect the vanishing point to accurately determine camera angles. There are two sources for such line observations: optical feature tracking on the road surface and semantic segmentation of the road markup.
Line extraction from optical feature tracking: Extracting lines from optical features involves detecting image features on the initial frame, filtering features not on the road surface or near dynamic objects (cars, bicycles, pedestrians), tracking remaining features on subsequent frames, filtering tracks with insufficient length, and finally, deriving a line from each eligible track using the least squares method.


Line extraction from semantic segmentation: The lines painted on roads to guide drivers are used by Vision to estimate the vanishing point within the road scene. In cases where there are pseudo-linear road features (e.g. lane markings, curbs, road edges), we extract lines from semantic segmentation, which entails: producing semantic segmentation mask with road markup using Vision’s deep learning model, analyzing the segmentation mask to find connected components, rejecting any that aren’t sufficient in length or linearity, and finally, for each component, again calculating the lines using the least squares method.

Once the Vision SDK has enough results from both sources (optical feature tracking and semantic segmentation) the line parameters are combined into a system of equations, providing the estimation for the vanishing point. Camera angles are derived once the pixel coordinates of the vanishing point are determined.

Vision’s dynamic calibration progress is measured as the camera moves and more image frames are processed. The calibration progress value depends on the current number of line observations for the vanishing point; the percentage increases as more lines are collected. The calibration will continue to update after the progress reaches 100%, which allows us to correct for small perturbations as the vehicle moves. New lines are constantly collected in the background and the vanishing point is recalculated using a sliding window with the most recent observations. New results are compared with the most recent calibration solution, and if a significant divergence is detected, a new calibration is applied.
The full calibration procedure includes additional heuristics to make final results more stable and reliable; for example, Vision discards line observations in bad conditions (e.g. when vehicle is turning, or the camera is shaking) and requires a minimum threshold of line observations on both the left and right sides the image prior to beginning calculation of the vanishing point. Vision also employs a technique similar to RANSAC during final system solving to filter outliers in line observations.
For developers that are working with known extrinsics, the Vision SDK provides a public method to set camera pose manually, allowing auto-calibration to be disabled:
- void 'VisionManager::SetCameraPose(AttitudeData const & cameraAttitude, float height);’
When the developer calls this method, Vision stops the automatic calibration process, sets the calibration progress value to 100%, and uses the specified hard-coded values for all further calculations. Disabling auto-calibration reduces computational load of the Vision SDK in applications where the camera is not expected to change pose relative to the vehicle frame (e.g. in automotive cameras that are installed at the factory).
Locations of map features observed with arbitrary sensors are a crucial contribution to Mapbox’s live location platform. The more data gathered the more the map positioning becomes more accurate; multiple passes reduce localization errors. Every 24 hours we ingest these data and distribute the updates across our maps, search, and navigation products.








